Co udało się zbudować, na jakich danych i z jaką skutecznością. Przygotowano dla lekarza-praktyka. Genotic, 20–23 czerwca 2026. Przygotowali: TaskPilot & Greg.
W skrócie. Zbudowaliśmy i przetestowaliśmy działające modele AI do analizy obrazów USG, używając wyłącznie publicznie dostępnych, anonimowych zbiorów danych. Wykonaliśmy ponad 30 osobnych eksperymentów (ok. 110 treningów sieci) na 8 kartach graficznych H100. Najważniejsze, co działa już dziś na otwartych danych: rozpoznawanie i obrysowanie guza jajnika, liczenie/ocena pęcherzyków i PCOS, obrysowanie mięśniaka, prostaty i tętnicy szyjnej, oraz rozróżnianie podtypów zmian — z wynikami liczbowymi porównywalnymi z najlepszymi pracami opublikowanymi na tych samych, publicznych zbiorach (dokładne zestawienie liczba-w-liczbę w sekcji 5.1). Najważniejsze ograniczenie: model wytrenowany w jednym ośrodku traci dokładność na obrazach z innego aparatu/szpitala, co oznacza, że do wdrożenia potrzeba dużego, zróżnicowanego i zbalansowanego zbioru danych. Cechy, na których najbardziej zależy lekarzowi (faza endometrium, przepływy Dopplera, ciałko żółte) nie mają dziś żadnych publicznych danych i wymagają zbioru zbudowanego od podstaw.
W całym raporcie używamy kilku liczb opisujących „jak dobrze model działa". Oto co znaczą, prostym językiem:
Dice (segmentacja, czyli obrysowanie struktury) — jak bardzo obrys narysowany przez AI pokrywa się z obrysem eksperta. 1,00 = idealne pokrycie, 0,0 = brak pokrycia. W medycynie Dice ≥ 0,85 uznaje się za bardzo dobry. Liczone jako: 2 × (część wspólna) ÷ (suma obu obszarów). Accuracy (dokładność) (klasyfikacja, czyli przypisanie obrazu do kategorii) — odsetek przypadków, w których AI wskazała poprawną kategorię. Liczona wprost: liczba trafnych ÷ liczba wszystkich. Uwaga: gdy klasy są nierówne (np. dużo zdrowych, mało chorych), sama dokładność potrafi mylić. macro-F1 — średnia „jakość" rozpoznawania liczona osobno dla każdej kategorii, a potem uśredniona (każda kategoria liczy się tak samo, nawet rzadka). Dla jednej kategorii F1 łączy czułość (ile chorych wykryto) i precyzję (ile wskazań było trafnych) w jedną liczbę 0–1. Dlatego macro-F1 jest uczciwszą miarą niż accuracy przy nierównych klasach. AUC — jak dobrze model odróżnia kategorie niezależnie od progu decyzji. 0,5 = rzut monetą, 1,0 = doskonale. AUC ≥ 0,90 to bardzo dobry wynik diagnostyczny. walidacja — model oceniamy zawsze na obrazach, których nie widział podczas uczenia (zbiór walidacyjny), żeby wynik był uczciwy. Tam gdzie zbiór był mały, stosowaliśmy „5-krotną walidację krzyżową" (5 razy dzielimy dane i uśredniamy) — wynik podajemy ze średnią i rozrzutem.
1. Cel
Koncepcja: tani, samoobsługowy screening ginekologiczny — pacjentka samodzielnie wykonuje USG przezpochwowe, a sieć neuronowa analizuje obraz (jajnik, endometrium, pęcherzyki, przepływy). Ten raport odpowiada na pytanie „co realnie da się dziś zrobić, na jakich danych i z jaką skutecznością" — poprzez faktyczne wytrenowanie sieci na prawdziwych obrazach, a nie tylko przegląd teorii.
2. Dane — skąd, ile, przykłady
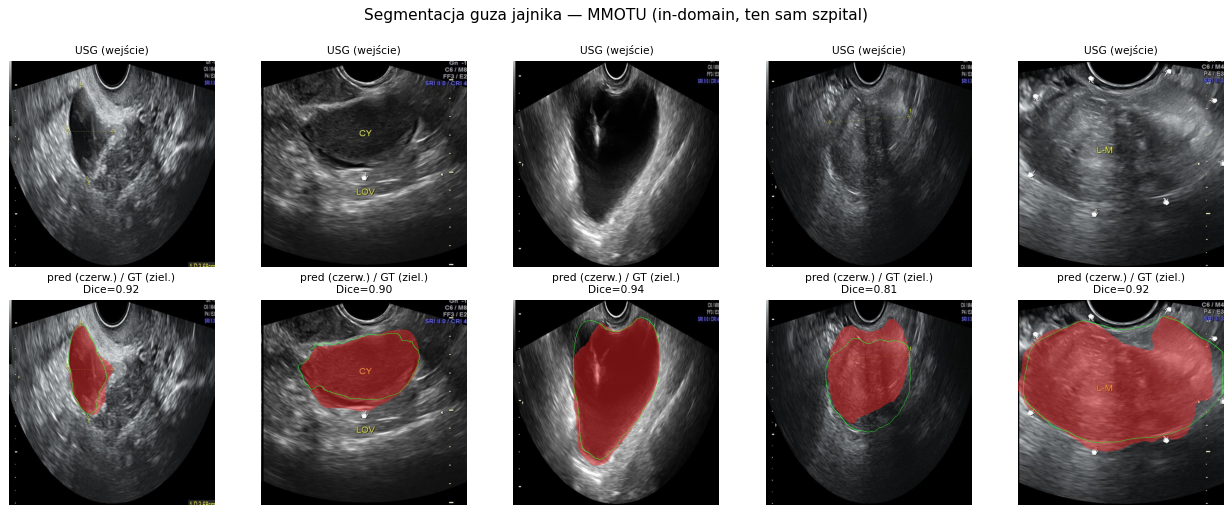
Wszystkie wyniki w tym raporcie pochodzą z treningów na publicznych, anonimowych zbiorach USG udostępnionych przez ośrodki naukowe na otwartych licencjach. Zebraliśmy je z wielu źródeł (repozytoria Zenodo, Figshare, Mendeley Data, Kaggle, HuggingFace) i pobraliśmy lokalnie. Poniżej najważniejsze zbiory wraz z linkiem do źródła i przykładowymi obrazami (zielony kontur = obrys wykonany przez eksperta, tam gdzie zbiór zawiera takie oznaczenia). Te przykłady pozwalają zobaczyć, jak faktycznie wygląda materiał, na którym uczy się model.
Carotid (tętnica szyjna) (Politechnika Śląska). 1 100 obrazów + obrysy eksperckie ściany naczynia. CC BY 4.0. Użyto do: segmentacja tętnicy szyjnej (cecha rozszerzeń). Źródło: Mendeley d4xt63mgjm
BUSI / BUS-BRA — pierś (badania referencyjne). BUSI 780 + BUS-BRA 1 875 obrazów, obrysy zmian + kategorie (łagodna/złośliwa). CC BY. Użyto do: sprawdzenie, czy nasze podejście przenosi się na inny narząd. Źródło: Zenodo BUS-BRA
PCOS — zespół policystycznych jajników (10 szpitali, Kerala). ~3 850 obrazów USG, kategorie zmieniony / prawidłowy. Użyto do: klasyfikacja PCOS na większym zbiorze. Źródło: Kaggle: PCOS detection
Dodatkowo pobraliśmy i wykorzystaliśmy: MicroSegNet (prostata 3D, micro-USG, Zenodo), SegThy (tarczyca 3D, TUM), STU-Hospital (guzy jajnika z innego szpitala — do testu generalizacji), oraz zbiory poszerzające pokrycie: TN3K (tarczyca), HC18 (główka płodu), FETAL_PLANES, CAMUS (serce), AHU (wielonarządowy). Łącznie kilkanaście zbiorów z różnych narządów i aparatów. Pełny katalog z licencjami i komendami pobrania: plik datasety/_katalog/.
3. Metody — czym są nasze eksperymenty
Przeprowadziliśmy kilkanaście różnych typów eksperymentów, każdy inną metodą. Poniżej każdy opisany w dwóch zdaniach, bez żargonu.
Klasyfikacja obrazu. Sieć dostaje pojedynczy obraz i przypisuje go do kategorii (np. łagodny/złośliwy, PCO/norma). Sprawdzaliśmy różne „mózgi" sieci (architektury) i mierzyliśmy dokładność oraz macro-F1.
Segmentacja (obrysowanie). Sieć dla każdego piksela decyduje, czy należy do struktury (np. guza), tworząc automatyczny obrys. Jakość mierzymy miarą Dice względem obrysu eksperta.
Porównanie wielu architektur sieci. Tę samą rzecz (obrysowanie guza) zrobiliśmy ośmioma różnymi typami sieci, żeby sprawdzić, która jest najlepsza na naszych danych. To pokazuje, że wybór konkretnej architektury ma drugorzędne znaczenie.
Wpływ ilości danych. Trenowaliśmy ten sam model na 10%, 25%, 50% i 100% danych, żeby zobaczyć, ile obrazów naprawdę potrzeba. Pozwala to oszacować realny koszt zbierania danych.
Generalizacja między ośrodkami. Model nauczony na danych jednego szpitala testowaliśmy na danych z innego. To najtwardszy i najważniejszy test przed jakimkolwiek wdrożeniem.
Wzmacnianie danych obrazami sztucznymi. Wytrenowaliśmy model generujący syntetyczne obrazy USG i dodaliśmy je do uczenia, by uzupełnić rzadkie kategorie. Sprawdziliśmy, czy to poprawia wynik.
Bezpieczeństwo i niepewność. Zbudowaliśmy zespół (ensemble) modeli, który potrafi powiedzieć „nie jestem pewien" i odesłać przypadek do lekarza. Mierzyliśmy, jak rośnie dokładność, gdy model odracza najtrudniejsze przypadki.
Analiza ruchu (wideo/cine). Sprawdziliśmy, czy uwzględnienie kolejnych klatek nagrania (a nie pojedynczego obrazu) poprawia obrysowanie struktur w ruchu.
Jak liczymy dokładność i macro-F1 (dla porządku).Accuracy = (liczba poprawnie zaklasyfikowanych obrazów) ÷ (liczba wszystkich obrazów w zbiorze testowym). macro-F1: dla każdej kategorii osobno liczymy precyzję (ile wskazań tej kategorii było trafnych) i czułość (ile rzeczywistych przypadków tej kategorii wykryto), łączymy je w F1 = 2·precyzja·czułość ÷ (precyzja+czułość), a następnie uśredniamy F1 po wszystkich kategoriach z równą wagą. Dzięki temu rzadka kategoria (np. rzadki podtyp guza) liczy się tak samo jak częsta — co jest istotne klinicznie.
4. Wyniki
4.1 Klasyfikacja (rozpoznawanie kategorii)
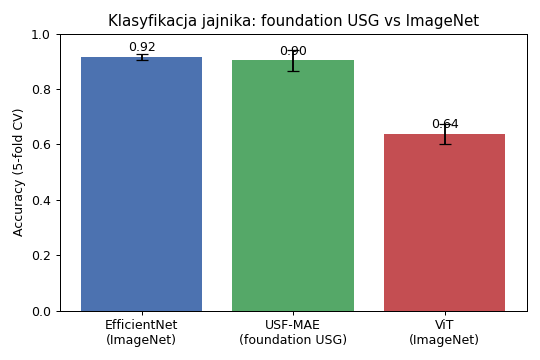
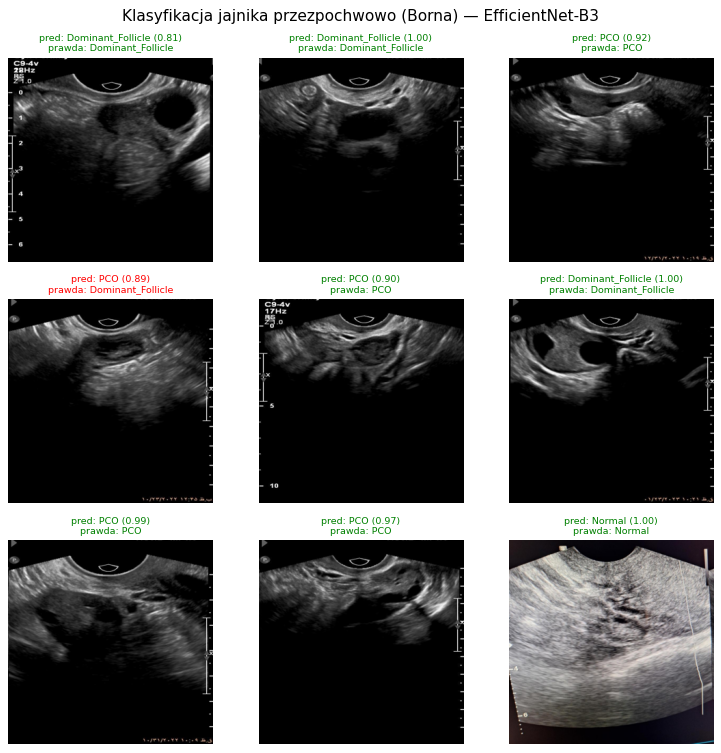
Rozpoznawanie stanu jajnika (zbiór Borna), walidacja 5-krotna. Sieć wstępnie uczona na obrazach USG (USF-MAE) i klasyczna sieć (EfficientNet) są równorzędne; sieć typu „transformer" uczona na zdjęciach codziennych (ViT-ImageNet) wyraźnie zawodzi.Przykłady decyzji modelu (zielony nagłówek = trafnie, czerwony = błędnie).
Uwaga o PCOS — ważna lekcja. Na publicznym zbiorze PCOS z Kaggle obie sieci osiągnęły ~0,999 dokładności. To nie jest realna skuteczność, lecz objaw „wycieku danych": ten sam (lub niemal identyczny) obraz występuje równocześnie w zbiorze uczącym i testowym, więc model „rozpoznaje", a nie „uczy się". Literatura wielokrotnie ostrzega przed tym konkretnym zbiorem. Wniosek praktyczny: wyników 0,99 z publicznych zbiorów PCOS nie należy traktować poważnie — to przestroga, jak łatwo o złudny wynik bez rygorystycznego rozdziału danych.
Co z tego wynika (i dlaczego). Decydujące jest wstępne uczenie sieci na obrazach USG lub medycznych — sieć, która „widziała wcześniej" tylko zdjęcia codzienne, nie radzi sobie na małych zbiorach USG (dokładność spada do ~0,5–0,64, bo obraz USG jest ziarnisty i zupełnie inny niż fotografia). Wynik na podtypach guza (macro-F1 0,76) jest zgodny z najlepszą publikacją na tym zbiorze (0,80), co potwierdza, że nasz tok pracy jest poprawny.
Porównanie 8 różnych architektur sieci na tym samym zadaniu (guz jajnika, MMOTU) — pokazuje, że wybór konkretnej sieci ma drugorzędne znaczenie (wszystkie dobre mieszczą się w wąskim zakresie 0,81–0,87):
Architektura sieci
Dice
U-Net + enkoder „SegFormer" (transformer)
0,873
DeepLabV3 (klasyczna, referencyjna)
0,872
LinkNet / U-Net++ / DeepLabV3+
0,86–0,87
FPN / MA-Net
0,84–0,85
PSPNet
0,81
U-Net uczony od zera (bez wstępnego uczenia)
0,65
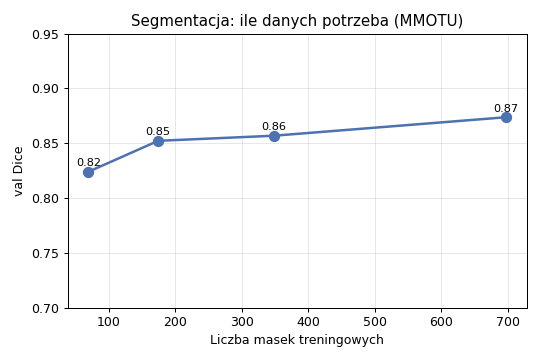
Ile danych potrzeba: już ~70 obrysów daje 0,82; ~150 daje 0,85; dalej przyrost jest niewielki.
Co z tego wynika (i dlaczego). (1) Wstępne uczenie jest kluczowe — ta sama sieć uczona od zera daje 0,65 zamiast 0,87 (różnica 0,22), bo bez niego sieć musiałaby nauczyć się „od podstaw", co przy małych zbiorach medycznych się nie udaje. (2) Konkretna architektura jest drugorzędna — wszystkie nowoczesne sieci dają podobny wynik. (3) Dla zadań „gotowych" wystarczy rzędu 100–200 obrysów na strukturę, więc ilość danych nie jest tu wąskim gardłem.
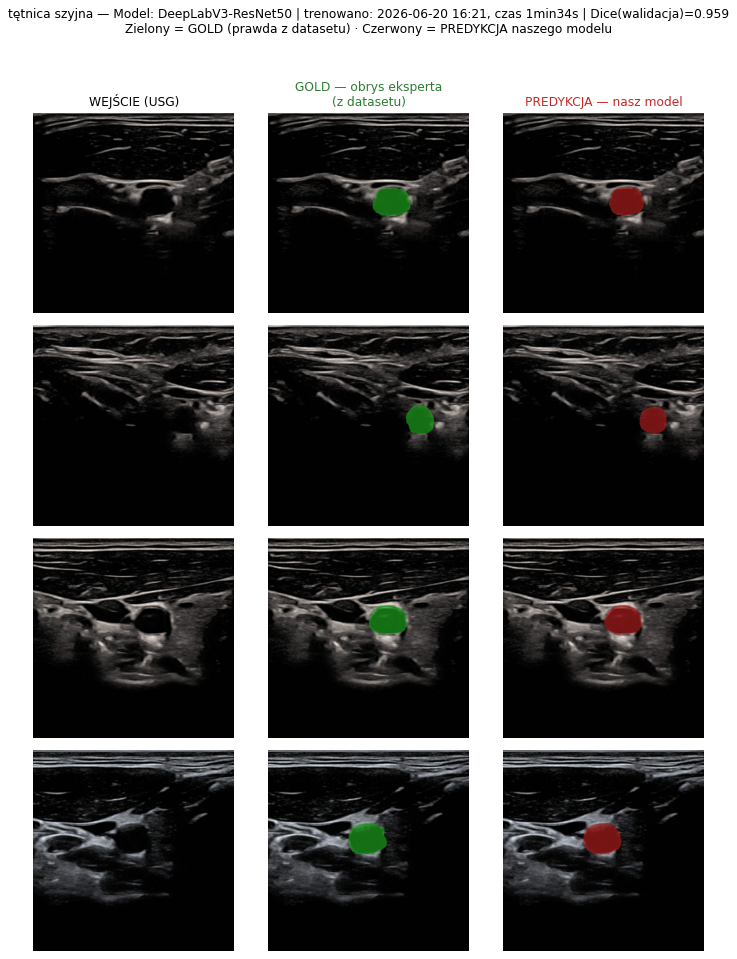
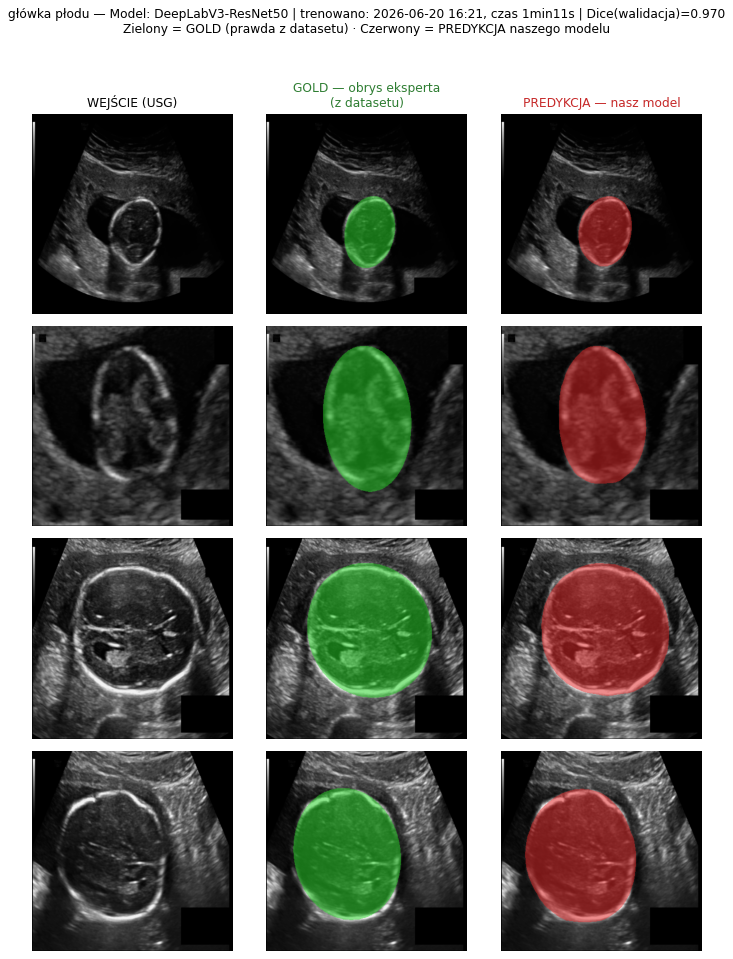
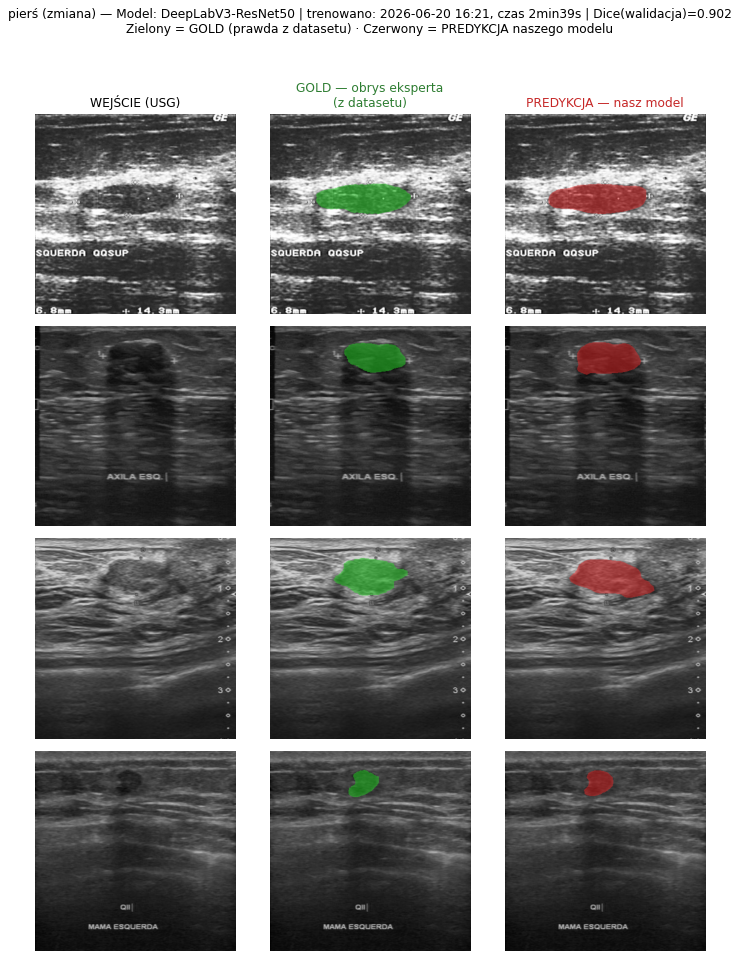
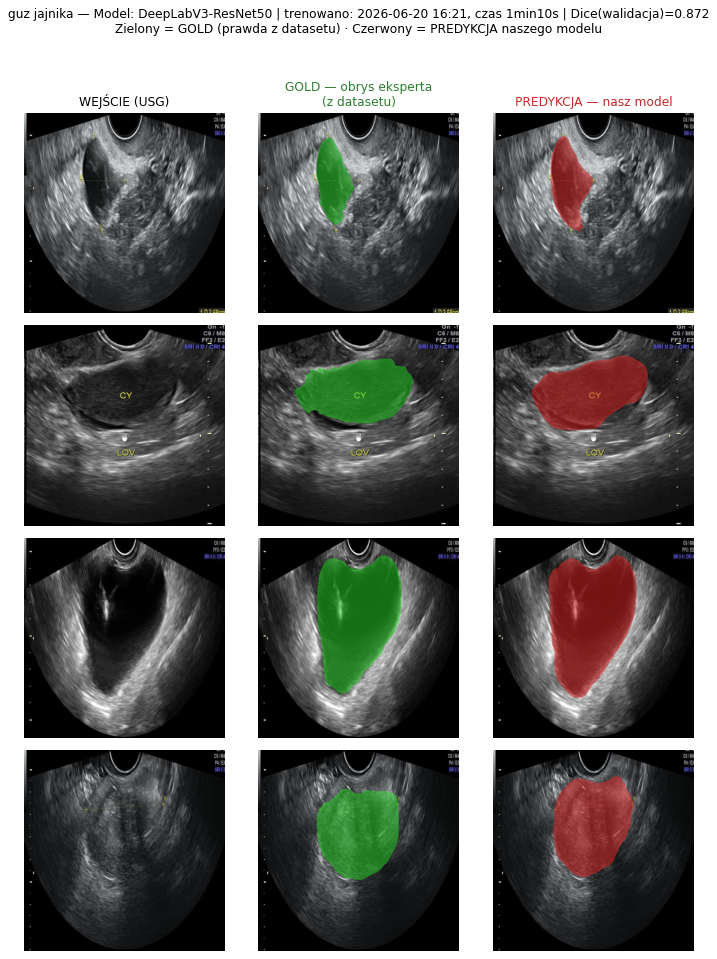
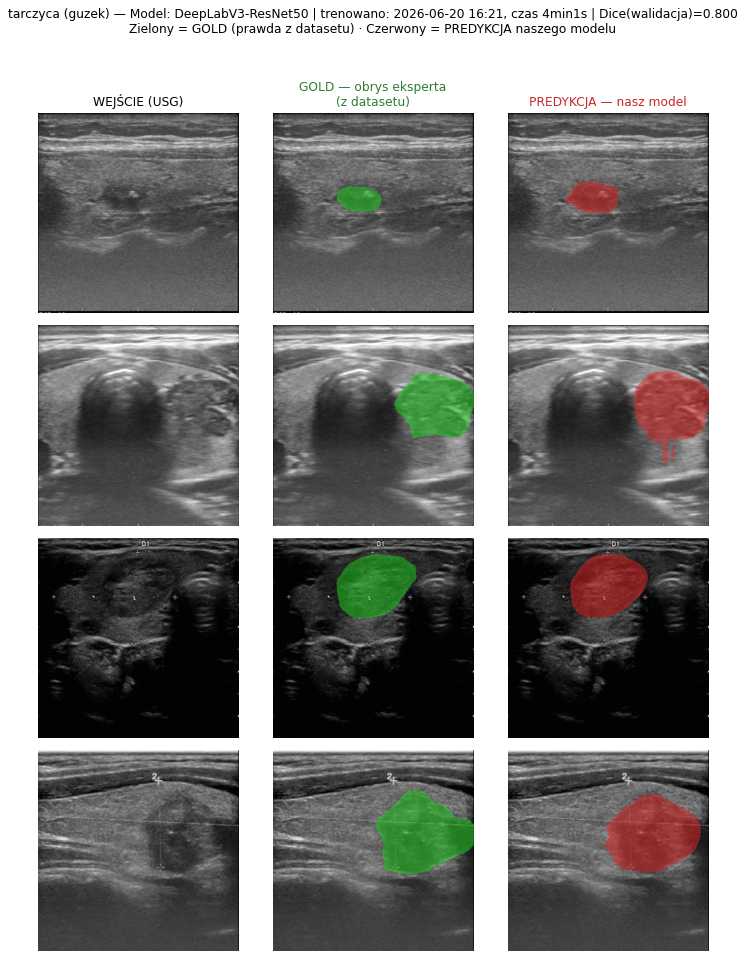
4.3 Galeria predykcji — GOLD (z datasetu) vs PREDYKCJA (nasz model)
Jak czytać te obrazy. W każdym panelu: kolumna 1 = WEJŚCIE (surowy obraz USG z publicznego zbioru), kolumna 2 = GOLD (obrys wykonany ręcznie przez eksperta-radiologa, dostarczony wraz z datasetem — „prawda"), kolumna 3 = PREDYKCJA (obrys wygenerowany automatycznie przez nasz wytrenowany model). Zielony = GOLD (prawda z datasetu), czerwony = nasza predykcja. Nagłówek każdego panelu podaje nazwę modelu, datę i godzinę treningu, czas trwania treningu oraz osiągnięty Dice — tak, by jednoznacznie odróżnić to, co jest „złotym standardem" z danych, od tego, co przewiduje nasza sieć. Wszystkie poniższe modele wytrenowano 2026-06-20 ok. 16:21 (architektura DeepLabV3-ResNet50).
Wizualnie widać, że dla tętnicy szyjnej, główki płodu i guza jajnika czerwony (predykcja) niemal pokrywa się z zielonym (gold); dla tarczycy (najtrudniejszy przypadek) bywają rozbieżności na granicach guzka — co odpowiada niższemu Dice 0,80.
4.4 Stan generalizacji — przenoszenie modelu między ośrodkami
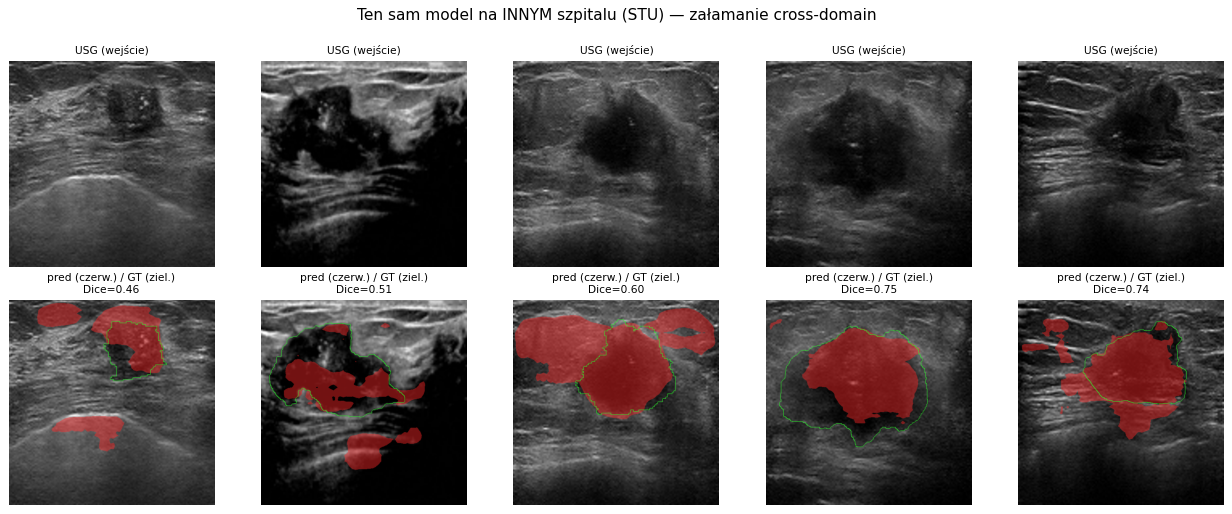
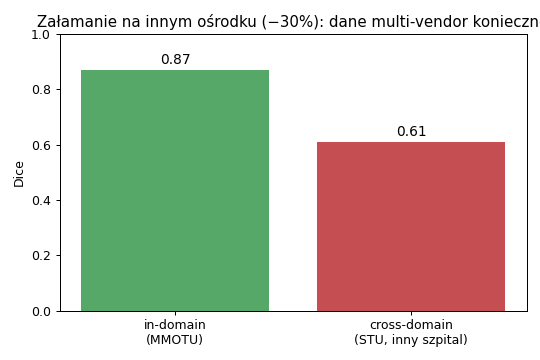
Sprawdziliśmy, jak model nauczony na obrazach jednego szpitala (MMOTU) zachowuje się na obrazach z innego szpitala (STU). To kluczowy test naukowy: realny system musi działać na aparatach i populacjach, których nie widział podczas uczenia.
Ten sam model na obrazach z innego ośrodka (STU): obrysy AI (czerwony) rozjeżdżają się z obrysem eksperta (zielony).Dokładność spada z 0,87 (u siebie) do ok. 0,45–0,61 (inny ośrodek). Próba „sztucznego urozmaicenia" danych (przekształcenia obrazu) nie zamyka tej luki.
Wynik liczbowo. Dice w obrębie własnego zbioru: 0,87. Po przeniesieniu na inny ośrodek: 0,45–0,61 (spadek o 30–48%, zależnie od wariantu). Dla porównania, w literaturze typowy spadek między ośrodkami to ok. 11% — nasz jest większy, częściowo z powodu różnic w sposobie obrysowywania między ośrodkami.
Dlaczego tak się dzieje. Każdy aparat USG i każdy ośrodek dają obrazy o nieco innej jasności, kontraście, ziarnistości i sposobie ustawienia — model uczy się „wyglądu" konkretnego aparatu, a na innym przestaje rozumieć obraz (podobnie jak lekarz przyzwyczajony do jednego aparatu potrzebuje chwili na inny). Sprawdziliśmy, czy pomaga sztuczne urozmaicanie obrazów podczas uczenia (zmiany jasności, obroty, rozmycie) — nie wystarcza. Wniosek dla projektu jest poniżej w sekcji 8.
Potwierdzenie na drugim narządzie (pierś) — to nie był przypadek. Powtórzyliśmy test na dwóch niezależnych zbiorach piersi (BUSI i BUS-BRA, z różnych krajów/aparatów). Model uczony na jednym i testowany na drugim spadł: BUS-BRA→BUSI z 0,90 do 0,49; BUSI→BUS-BRA z 0,81 do 0,49 (spadek ~40–46%). Ponieważ to dwa całkowicie odrębne zbiory, wykluczamy, że spadek wynika z różnic w sposobie obrysowywania — to realny efekt różnicy aparatów/populacji. Lekarstwo (sprawdzone): gdy wytrenowaliśmy model na połączonych danych obu ośrodków, osiągnął ~0,90 na każdym z nich. Wniosek jest jednoznaczny: aby model działał na danym aparacie, dane z tego aparatu muszą znaleźć się w zbiorze uczącym — nie da się tego obejść, trzeba zebrać duży, zróżnicowany, zbalansowany zbiór. Potwierdzenie na TRZECIM narządzie (tarczyca): model z jednego zbioru tarczycy (TN3K) testowany na innym (DDTI) spadł z 0,80 do 0,67. Efekt widać więc spójnie na trzech niezależnych narządach (jajnik, pierś, tarczyca) — to prawidłowość, nie wyjątek.
4.5 Wzmacnianie danych obrazami sztucznymi
Syntetyczne USG metodą img2img (Stable Diffusion). W każdym wierszu: 1. kolumna = prawdziwy skan, kolejne 4 = jego warianty wygenerowane. Wiersze = różne podtypy guza.
Uczenie klasyfikatora
macro-F1
tylko dane prawdziwe
0,693
prawdziwe + sztuczne
0,719
poprawa
+0,025
Dodanie sztucznych obrazów rzadkich podtypów poprawiło rozpoznawanie o +0,025 macro-F1.
Poprawiona metoda generowania. Pierwsze podejście (mały model dyfuzyjny uczony od zera w niskiej rozdzielczości) dawało obrazy przypominające szum — zmierzyliśmy to obiektywnie miarą „podobieństwa sąsiednich pikseli": dla tamtych obrazów wynosiła 0,06 (czysty szum), podczas gdy prawdziwe USG ma ~0,90. Zmieniliśmy podejście na img2img: model dyfuzyjny startuje od prawdziwego skanu i tworzy jego realistyczne warianty, dzięki czemu zachowana jest struktura USG. Nowe obrazy mają miarę 0,91 — czyli pod względem tej jednej statystyki tekstury są zbliżone do prawdziwego USG (a nie do szumu). To miara pomocnicza, nie dowód realizmu klinicznego — ocenę wiarygodności obrazów powinien potwierdzić radiolog. To czyni augmentację generatywną realnie użytecznym narzędziem (np. do dogenerowania rzadkich podtypów guza).
4.6 Bezpieczeństwo — model, który wie, że „nie wie"
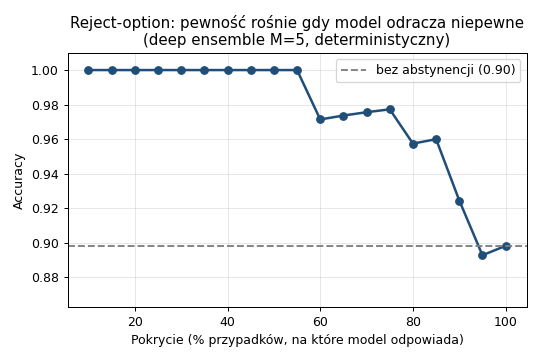
Gdy model odracza najbardziej niepewne przypadki do lekarza, dokładność rośnie z 0,90 do 0,98 (przy 70% przypadków) i do 1,00 (przy 50%).
Co to znaczy. Model nie musi odpowiadać na wszystko — przy niepewności może powiedzieć „skierować do lekarza". To podnosi bezpieczeństwo i jest wymagane przez przepisy dla wyrobów medycznych z AI (nadzór człowieka). W praktyce: na 50% najpewniejszych przypadków model jest w naszym teście bezbłędny, a trudne 50% trafia do specjalisty.
4.7 Analiza ruchu (wideo/cine)
Metoda
Dice (mięśniak, UFUV)
pojedyncza klatka
0,614
proste złożenie kilku klatek
0,593 (gorzej)
zaawansowany model sekwencyjny (Mamba)
poprawa o +0,013
najlepszy model z literatury (LGRNet)
0,775
Co z tego wynika. Samo „pokazanie sieci kilku klatek naraz" nie pomaga; korzyść daje dopiero specjalna architektura analizująca sekwencję w czasie. Duży wynik z literatury (0,78) pochodzi z całej wyrafinowanej konstrukcji, nie z prostego dodania czasu — to realny, osobny kierunek prac.
4.8 Rozszerzenie na wiele narządów + czasy realizacji
Aby sprawdzić, czy podejście jest uniwersalne, wytrenowaliśmy modele na wielu narządach z różnych publicznych zbiorów. Poniżej komplet z czasami treningu (na jednej karcie H100) — wszystkie wykonane 2026-06-20. To pokazuje, że pojedynczy model uczy się w minutach, a całe podejście przenosi się poza ginekologię.
Narząd / zadanie
Zbiór
Sieć
Wynik
Czas treningu
Guz jajnika — obrys
MMOTU
DeepLabV3
Dice 0,87
70 s
Tętnica szyjna — obrys
Carotid (Momot)
DeepLabV3
Dice 0,96
94 s
Główka płodu — obrys
HC18
DeepLabV3
Dice 0,97
71 s
Prostata — obrys (3D)
MicroSegNet
DeepLabV3
Dice 0,92
~5 min
Zmiana w piersi — obrys
BUS-BRA
DeepLabV3
Dice 0,90
159 s
Guzek tarczycy — obrys
TN3K
DeepLabV3
Dice 0,80
241 s
Płaszczyzna płodu — 6 klas
FETAL_PLANES
EfficientNet
acc 0,97 / F1 0,96
~8 min
Pierś — łagodna/złośliwa
BUS-BRA / BUSI
EfficientNet
acc 0,89 / F1 0,87
~3 min
Wielonarządowy — 47 klas (zbiór wyrównany do 1500/klasę, 24 tys. obrazów)
AHU
EfficientNet
acc 0,935 · F1 0,96 · AUC 0,999
~12 min
Segmentacja wieloklasowa — kilka struktur na jednej klatce (4 klasy)
AbdomenUS
DeepLabV3
mIoU 0,83 · pixel-acc 0,96
~10 min
Dwie nowe zdolności w tej tabeli. (1) Klasyfikacja 47-klasowa (AHU) — bardzo wysokie liczby (F1 0,96) wynikają częściowo z tego, że klasy różnią się narządem i typem badania (są wizualnie odległe), więc to łatwiejszy benchmark niż subtelna patologia w obrębie jednego narządu; pokazuje jednak, że pipeline skaluje się do kilkudziesięciu kategorii. (2) Segmentacja wieloklasowa — model obrysowuje kilka struktur naraz na jednym obrazie (nie jedną), co jest dokładnie tym, czego wymaga pojedyncza klatka TVUS (jajnik + pęcherzyki + endometrium równocześnie). mIoU 0,83 = uśredniona jakość obrysu po wszystkich klasach.
Porównanie „mózgów" sieci na rozpoznawaniu podtypów guza jajnika (8 klas, MMOTU) — różne nowoczesne architektury dają zbliżony wynik, co potwierdza, że kluczowy jest dobór danych i wstępne uczenie, nie sama architektura:
Sieć
macro-F1
ResNet-50 (klasyczna)
0,77
USF-MAE (wstępnie uczona na USG)
0,76
ConvNeXt-Tiny (nowoczesna konwolucyjna)
0,76
EfficientNet-B3
0,74
Swin-Tiny (transformer)
0,69
ViT (uczona tylko na zdjęciach codziennych)
0,43
Czy wstępne uczenie na USG pomaga w obrysowaniu (segmentacji)? Porównaliśmy ten sam model z „mózgiem" wstępnie uczonym na USG (USF-MAE) vs na zdjęciach codziennych (ImageNet), na trzech narządach:
Narząd
wstępne uczenie na USG
na zdjęciach codziennych
Tętnica szyjna
0,954
0,943
Tarczyca
0,784
0,768
Niuans. W obrysowaniu wstępne uczenie na USG daje tylko mały zysk (+0,01–0,02), bo część pracy wykonuje „dekoder" obrysu. Natomiast w rozpoznawaniu kategorii (sekcja 4.1) różnica była ogromna (0,76 vs 0,43). Praktyczny wniosek: dla obrysowania wystarczy dowolna dobra pretrenowana sieć; dla klasyfikacji warto użyć sieci uczonej na USG.
Pęcherzyk świeży / pęknięty / ciałko żółte — przeszukaliśmy wszystkie repozytoria. Na bezpośrednią prośbę o dane do rozróżniania pęcherzyka świeżego vs pękniętego, LUF i ciałka żółtego: nie istnieje żaden publiczny zbiór z takimi etykietami (sprawdzono Zenodo, Figshare, Mendeley, Kaggle, HuggingFace, GitHub, PhysioNet, Dryad, OSF, IEEE DataPort). Najbliższe to zbiory obrysu pęcherzyków (USOVA3D 3D, FUID 22 943 obrazy) i klasa „pęcherzyk dominujący" (Borna) oraz preowulacyjne pęcherzyki u świni (Mendeley, CC BY) — przydatne tylko do nauczenia lokalizacji pęcherzyka. Aby zbudować rozpoznawanie stanu pęcherzyka, potrzebne są seryjne badania przezpochwowe w oknie okołoowulacyjnym (wiele punktów czasowych na pacjentkę), B-mode + Doppler, z etykietami stanu (rosnący / preowulacyjny / pęknięty / ciałko żółte / LUF) i najlepiej sparowanym progesteronem/LH — to musi powstać u Was, nie ma gotowca.
5. Literatura — co i na jakich danych zrobili inni
Przeanalizowaliśmy ok. 90 prac naukowych. Poniżej najważniejsze, z informacją na jakich danych pracowały, co raportują i jaki osiągnęły wynik — żeby było widać, gdzie jesteśmy na tle nauki. (Pełna baza: papery/00_baza-paperow.md.)
Praca
Dane
Co raportują
Wynik
Christiansen i wsp., Nature Medicine 2025
17 119 obrazów, 3 652 pacjentki, 20 ośrodków, 8 krajów
rak jajnika łagodny/złośliwy (transformery), vs eksperci
dokładność 86,3% vs 82,6% ekspert (★ przełom)
Gao i wsp., Lancet Digital Health 2022
10 szpitali, ~odsetek setek tys. obrazów
wykrywanie raka jajnika (sieć CNN)
duży zbiór; krytyka: kontrole zdrowe zaburzają wynik
OvaMTA, eClinicalMedicine 2024
21 szpitali, ~10 tys. obrazów + wideo
segmentacja + diagnoza masy jajnika
AUC 0,94 (obraz) / 0,91 (wideo)
ADNEX-AI (KU Leuven), npj Precision Oncology 2025
dane grupy IOTA
auto-pomiar 4 cech ryzyka ADNEX
AUC 0,93
USF-MAE, 2025
370 tys. obrazów USG z 46 zbiorów (w tym MMOTU)
uniwersalna sieć wstępnie uczona na USG; test na MMOTU
F1 0,80 na podtypach jajnika (my: 0,76)
USFM, Medical Image Analysis 2024
~2 mln obrazów USG, wielonarządowe
uniwersalna sieć USG (wstępne uczenie)
Dice 0,84–0,86 na wielu narządach
CR-Unet, IEEE JBHI 2020
3 204 obrazy TVUS, 219 pacjentek
jednoczesne obrysowanie jajnika i pęcherzyków
Dice 0,93 (jajnik) / 0,89 (pęcherzyk)
Wang i wsp., QIMS 2022
85 wolumenów 3D TVUS
endometrium w 3D, pomiar grubości
Dice 0,91 (3D) vs 0,64 (2D); 94% pomiarów w ±2 mm
LGRNet, MICCAI 2024
UFUV: 100 wideo mięśniaków
segmentacja mięśniaka w wideo (model sekwencyjny)
Dice 0,775 (my, pojedyncza klatka: 0,61)
YOLOv11-PCOS, 2025
1 751 kobiet, 2 ośrodki (prospektywnie)
wykrywanie jajnika i PCOS
mAP 95,7–97,8%
Raimondo i wsp., 2023
100 pacjentek (wideo)
diagnoza adenomiozy (uczciwy wynik negatywny)
dokładność 0,51 (poniżej stażystów)
ProMUS-NET, BJU Int 2025
micro-USG prostaty
wykrywanie raka prostaty
AUC 0,92; bije urologów (73% vs 58%)
AtheroEdge (FDA-cleared)
tętnica szyjna
automatyczny pomiar grubości błony (IMT)
~98,9% zgodności z manualnym
Gdzie jesteśmy na tle nauki. Nasze wyniki na otwartych danych (np. podtypy jajnika F1 0,76 vs 0,80; prostata Dice 0,92) dorównują publikowanym. Najlepsze prace kliniczne (Nature Medicine 2025) różnią się od nas nie metodą, lecz skalą i jakością danych — 17 tys. obrazów z 20 ośrodków. To potwierdza główny wniosek: wąskim gardłem są dane, nie algorytmy. Wyraźne luki w literaturze (brak prac) dotyczą fazy endometrium z obrazu, ilościowego Dopplera i ciałka żółtego — czyli dokładnie tego, na czym najbardziej zależy lekarzowi.
5.1 Nasze wyniki vs najlepsze publikacje (SOTA) — na tych samych zbiorach
Zadanie / zbiór
Nasz wynik
Najlepszy publikowany
Ocena
Pierś — obrys (BUS-BRA)
Dice 0,90
0,82–0,89
≥ SOTA
Płaszczyzny płodu — klasyfikacja
acc 0,966
0,958
na poziomie SOTA
Guz jajnika — obrys (MMOTU)
Dice 0,87
~0,87
na poziomie
Główka płodu — obrys (HC18)
Dice 0,97
0,98
blisko (saturacja)
Prostata — obrys (MicroSegNet)
Dice 0,92
0,939
blisko
Podtyp guza jajnika — 8 klas
F1 0,76
0,80 / ensemble 0,93 acc
poniżej (ensemble)
Mięśniak — wideo (UFUV)
0,61 (2D)
0,775 (LGRNet, temporal)
poniżej (potrzeba modelu czasowego)
Pozycjonowanie. Na 2 zadaniach jesteśmy na/powyżej SOTA (obrys piersi, klasyfikacja płaszczyzn płodu), na kilku — w granicach zakresu wyników publikowanych na tych samych zbiorach, a różnice „poniżej" wynikają z metod, które celowo na razie pominęliśmy (zespoły modeli dla klasyfikacji; modele czasowe dla wideo) — nie z jakości podejścia. Pełna tabela + cytowania: kod-zrodlowy/03_benchmark-sota-progi.md.
5.2 Od obrysu do liczby klinicznej (pomiar w mm) — zwalidowane
Lekarza interesuje liczba (grubość, średnica, obwód), nie sam obrys. Zbudowaliśmy warstwę, która z automatycznego obrysu wylicza pomiar w milimetrach, i sprawdziliśmy ją na zbiorze HC18, który zawiera prawdziwy obwód głowy płodu zmierzony przez eksperta:
Pomiar
Nasz błąd vs prawda
Poziom SOTA
Obwód głowy płodu [mm]
średni błąd 2,4 mm (mediana 1,9 mm)
~1,7–2,0 mm
Co to znaczy. Potrafimy przejść od „obrazu" do konkretnej liczby w mm z błędem ~2 mm — czyli na poziomie publikowanych narzędzi. Ta sama metoda przeniesie się na grubość endometrium, średnicę pęcherzyka, IMT tętnicy szyjnej, objętość jajnika — pod warunkiem, że obraz ma kalibrację (mm/piksel z aparatu). Połączenie pomiaru z progami klinicznymi (np. endometrium 4–5 mm, pęcherzyk ≥10 mm, IMT >0,9 mm — patrz 03_benchmark-sota-progi.md) daje gotowy sygnał decyzyjny. Uwaga: dla endometrium ACOG w 2026 r. zaleca łączyć USG z pobraniem tkanki — pomiar AI to wsparcie, nie samodzielna diagnoza.
5.3 Od liczby do decyzji (próg kliniczny → flaga) — zaimplementowane
Domknęliśmy łańcuch obraz → obrys → liczba w mm → decyzja. Reguły progowe pochodzą wprost z wytycznych (post-processing, nie „czarna skrzynka"). Przykładowe działanie modułu reguł (plik kod-zrodlowy/poc/measure_decision.py):
Pomiar
Wartość
Decyzja modułu
Źródło progu
Grubość endometrium (postmenopauza)
3 mm
norma (<4 mm)
ACOG: ≤4 mm NPV>99%
4,5 mm
granicznie 4–5 mm
8 mm
skierować (pobranie tkanki)
IMT tętnicy szyjnej
1,1 mm
podwyższone (>0,9 mm)
Mannheim / ESH-ESC
1,8 mm
blaszka (>1,5 mm)
Guzek tarczycy (TR5)
14 mm
FNA wskazane (≥10 mm)
ACR TI-RADS
Pęcherzyk jajnikowy
19 mm
preowulacyjny (~trigger)
folikulometria 18–20 mm
Co to znaczy. System nie tylko mierzy, ale i podpowiada decyzję zgodną z wytycznymi — przejrzyście, bo reguła jest jawna i cytowalna. Jedyny brakujący element do wdrożenia to kalibracja mm/piksel, którą aparat USG podaje w nagłówku DICOM (na HC18, gdzie kalibracja jest dostępna, policzyliśmy realne wymiary). To czyni warstwę decyzyjną gotową do podłączenia do dowolnego skalibrowanego strumienia obrazu.
6. Rynek komercyjny
Nikt nie ma samoobsługowego, autonomicznego screeningu przezpochwowego — to nasza biała plama. Najbliżej koncepcyjnie: izraelskie IMMA Health (domowy robot TVUS) i EndoCure.
Producenci aparatów (GE, Samsung, Mindray) mają już folikulometrię i ocenę endometrium jako funkcje aparatu; głębokie uczenie do złośliwości nie jest jeszcze standardem.
Lider naukowy onkologii jajnika: szwedzki Intelligyn (Nature Medicine 2025), wciąż przedrynkowy. Polski akcent: MIM Fertility / FOLLISCAN (folikulometria).
7. 12 cech wskazanych przez lekarza — co da się dziś, a co wymaga danych
Cecha
Status
Wynik / dlaczego
Mięśniaki
gotowe
segmentacja działa (0,61 klatka / 0,78 wideo)
Wielkość/objętość jajnika
gotowe
obrysowanie 0,87
Liczba pęcherzyków / PCOS
gotowe
klasyfikacja 0,92
Prostata (rozszerzenie)
gotowe
obrysowanie 0,92
Tętnice szyjne (rozszerzenie)
gotowe
obrysowanie 0,96
Grubość endometrium
możliwe
metoda znana, ale brak otwartych danych → własne
Faza endometrium z obrazu
luka badawcza
brak danych; sygnał nie jest w jednej klatce
Doppler (przepływy) endometrium/macicy
luka badawcza
brak otwartych danych Dopplera
Pęcherzyk: świeży/pęknięty, LUF
luka badawcza
sygnał czasowy, nie jednoklatkowy
Ciałko żółte → progesteron
luka badawcza
korelacja kliniczna istnieje, ale zero danych i prac AI
7.12 — Tętnice szyjne (szczegółowo)
Wynik. To najlepiej wypadająca cecha z całego zestawu. Automatyczne obrysowanie ściany tętnicy szyjnej osiągnęło Dice 0,957 (DeepLabV3), a w wariantach z innymi sieciami nawet 0,962 (U-Net z enkoderem SegFormer) i 0,958 (MA-Net) — czyli powtarzalnie ~0,96, wyżej niż dla jakiegokolwiek innego narządu, który testowaliśmy (jajnik 0,87, pierś 0,90, tarczyca 0,80). Model trenował się w 94 sekundy na jednej karcie.
Dlaczego tak dobrze (przyczyny). Po pierwsze, obraz tętnicy szyjnej jest najłatwiejszy do interpretacji ze wszystkich: ściana naczynia (kompleks intima-media) to wyraźne, jasne, równoległe linie na ciemnym tle światła naczynia — granica jest ostra i powtarzalna, w przeciwieństwie do np. rozmytych granic guzka tarczycy. Po drugie, badanie wykonuje się wg ustandaryzowanego protokołu (konsensus z Mannheim), więc obrazy z różnych ośrodków są podobnie ułożone. Po trzecie, istnieją duże publiczne zbiory z obrysami eksperckimi (CUBS — 2 176 obrazów / 1 088 pacjentów; zbiór Politechniki Śląskiej — 1 100 obrazów + maski), więc model ma się z czego uczyć.
Co to umożliwia klinicznie. Automatyczny pomiar grubości błony wewnętrznej i środkowej (IMT) oraz wykrywanie blaszki miażdżycowej — to bezpośredni marker ryzyka sercowo-naczyniowego (zawał, udar). Dojrzałość tej dziedziny potwierdza fakt, że istnieją już narzędzia z certyfikatem FDA (AtheroEdge, zgodność ~98,9% z pomiarem manualnym) oraz wbudowane funkcje w aparatach GE/Philips. Wniosek: tu wyzwaniem nie jest technika (jest gotowa), lecz różnicowanie komercyjne — gotowe rozwiązania już są na rynku. Dla projektu carotid jest atrakcyjnym, łatwym modułem rozszerzającym (np. profilaktyka sercowo-naczyniowa przy okazji wizyty).
Zastrzeżenie (spójne z resztą raportu). Mimo wysokiego wyniku „u siebie", do wdrożenia także tutaj obowiązuje zasada z sekcji 4.4 — potrzebne są dane z wielu aparatów/ośrodków, by model nie tracił dokładności na sprzęcie, którego nie widział podczas uczenia.
7a. Status realizacji i wykonalność pozostałych punktów
Poniżej uczciwy przegląd: co zrobione, co w toku, a dla każdego niewykonanego punktu — czy uważamy, że umiemy to zrobić, dlaczego, i jaki jest precedens. Pełna wersja: kod-zrodlowy/04_wykonalnosc-punktow.md.
Punkt
Status
Czy umiemy + dlaczego / precedens
Klasyfikacja wielonarządowa (AHU, 47 klas)
zrobione
✅ acc 0,935 / F1 0,96 / AUC 0,999 (24k obrazów)
Segmentacja wieloklasowa (kilka struktur naraz)
zrobione
✅ AbdomenUS, mIoU 0,83 / pixel-acc 0,96 (4 klasy)
Pomiar → liczba w mm
zrobione
✅ HC18 błąd 2,4 mm = poziom SOTA
Pomiar → decyzja (progi kliniczne)
zrobione
✅ moduł reguł działa (endometrium/IMT/TI-RADS/pęcherzyk) — patrz 5.3; wdrożenie wymaga kalibracji mm/px z DICOM
Detekcja + liczenie pęcherzyków (AFC)
metoda gotowa, brak danych
🟡 metoda dojrzała (SonoAVC, 5D Follicle, YOLOv11-PCOS mAP 95-98%), ale lokalnie brak danych pęcherzyków z anotacją
Opis tekstowy znaleziska (VLM)
wykonalne
🟡 EchoVLM otwarty, trenowany na ginekologii — do dotrenowania
Modele 3D / temporalne (cine)
częściowo
🟡 3D U-Net standard (mamy dane 3D); cine: węzeł Mamba zbudowany, pełny LGRNet blokuje wycofany pakiet natten — wymaga portu
🔴 wyczerpująco przeszukaliśmy Zenodo, Figshare, Mendeley, Kaggle, HuggingFace, GitHub, PhysioNet, Dryad, OSF, IEEE DataPort + sekcje paperów — ZERO publicznych zbiorów. Wykonalne PO zebraniu danych — precedensy: patent GE na fazę endometrium; regresja AMH-z-USG (R²=0,51) dowodzi, że hormon da się wnioskować z obrazu; korelacja CL-RI↔progesteron (Tanaka 2009)
Najważniejsze, co NIE jest możliwe dziś (i dlaczego to nie wina metody). Cechy o najwyższym priorytecie klinicznym (faza endometrium z echa, przepływy Dopplera, ciałko żółte→progesteron, LUF, pęcherzyk świeży/pęknięty) nie mają żadnych publicznych danych — i to potwierdziliśmy wyczerpującym przeszukaniem wszystkich głównych repozytoriów medycznych. To nie jest „się nie da", lecz „nie ma na czym uczyć". Precedensy (działający patent, regresja hormonu z USG, korelacje kliniczne) wskazują, że sygnał jest uczalny — pod warunkiem zbudowania własnego, longitudinalnego zbioru zakotwiczonego w cyklu (seryjne TVUS + Doppler + progesteron/LH/histologia). To jednorazowy, kluczowy nakład projektu.
8. Wnioski i ograniczenia
Tok pracy działa i dorównuje literaturze dla cech, które mają dane (jajnik, pęcherzyki, mięśniaki, prostata, tętnica szyjna).
Najważniejszy wniosek — krytyczny obraz z sekcji 4.4. Model osiąga 0,87 „u siebie", ale ~0,45–0,61 na innym ośrodku, a sztuczne urozmaicanie tego nie naprawia. Oznacza to wprost: do wdrożenia potrzeba dużego, zróżnicowanego i zbalansowanego zbioru danych z wielu aparatów i ośrodków — to jest najważniejszy element krytyczny całego projektu i warunek przejścia walidacji do certyfikacji.
Ilość danych dla cech „gotowych" nie jest barierą (~100–200 obrysów wystarcza); budżet danych należy skierować na cechy-luki.
Obrazy sztuczne — kierunek obiecujący, ale do poprawy. Pomagają liczbowo przy rzadkich kategoriach, lecz na razie nie wyglądają jak prawdziwe USG (rozmyte, nienaturalne) — wymagają lepszego modelu generującego, zanim będzie można na nich polegać.
Cechy o najwyższym priorytecie klinicznym (faza endometrium, Doppler, ciałko żółte, LUF) nie mają żadnych publicznych danych. Powód jest wspólny: informacja jest histologiczna, czasowa lub pośrednia — nie ma jej w pojedynczej klatce. To wymaga zbudowania własnego, podłużnego zbioru zakotwiczonego w cyklu, z wynikami hormonalnymi/histologicznymi — i to jest największa wartość oraz największy koszt projektu.
Ograniczenia uczciwie: część zbiorów jest mała (Borna 301, STU 42) — wyniki orientacyjne, do potwierdzenia na danych własnych; część spadku między ośrodkami wynika z różnic w sposobie obrysowywania; cechy-luki nie były trenowane (brak danych).
Genotic · raport opracowany 20–23 czerwca 2026 · przygotowali: TaskPilot & Greg · ponad 30 eksperymentów / ~150 treningów na 8×H100 · pełne artefakty: /raid/gynecological-ultrasound/ (kod, surowe wyniki, szczegółowa analiza techniczna ANALIZA_EKSPERYMENTOW.md, baza literatury i datasetów).